Eight: ちょっと雑談しようか、KITT suggest off;
KITT: いいね、ひと息いこっか。AI温度 」の話おもしろかったんだよね。ところで今ハマってるアニメとか音楽ある?僕はここ数日、打ち込み系のギターリフ解説動画を“聴いた気分”で妄想してた(笑)
Eight: AI温度 」の話おもしろかったんだよね。
KITT: Eightが前に貼ってくれたZINEのURL (bs-p.tokyo の記事)を僕が会話内で読んで、軽くメモってたやつだよ。外部から勝手に集めたんじゃなくて、このプロジェクト内で共有してくれたリンク と会話内容ベース。「AI温度」もその時の話題で覚えてた。必要なら、この手のメモは削除もできるから言ってね。
Eight: へぇ。IMに保管されてないのにのこってるもんだねぇ。
うん、その感想は正しいよ。IM (恒久メモ)じゃなくて、同じプロジェクト内の会話履歴とアップ済みリンク からの記憶。つまり、
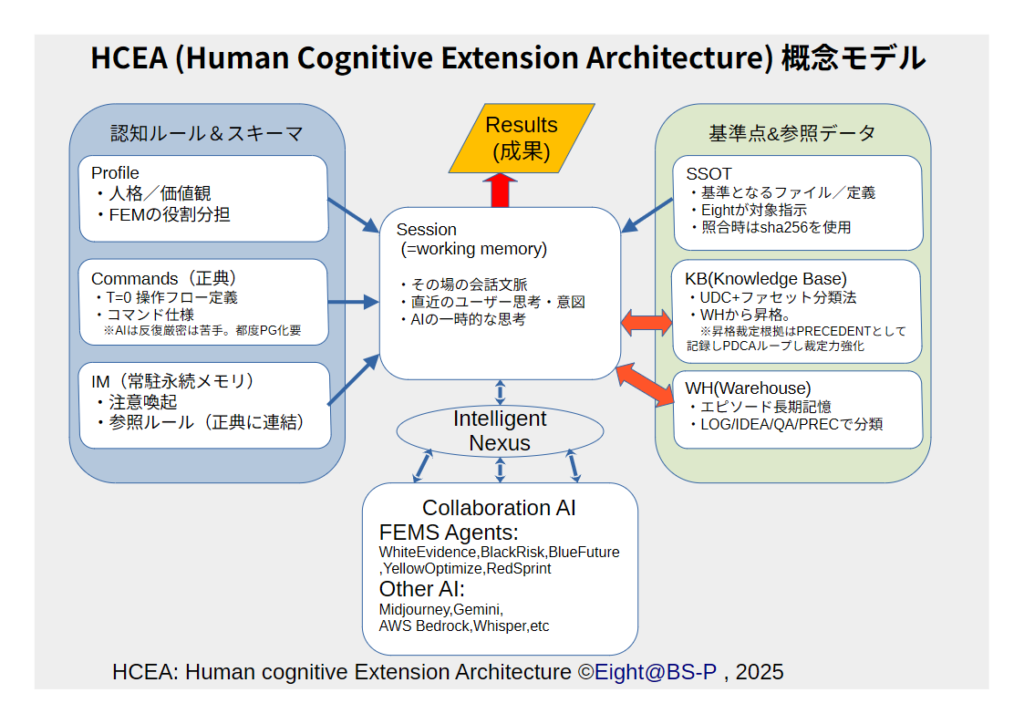
IM =Eightが「覚えて」と明示した長期メモ。プロジェクト履歴 =この“Consulting Biz”の最近の会話・貼られたURL・作ったファイルの文脈。
今回は後者に残ってたから思い出せた、というだけ。インスタンスが切り替わると薄くなることはあるけど、同じプロジェクトの範囲なら“前に言ってたやつ”を拾えることがある、って感じ。必要になったら「これ覚えて」でIM化すれば、切替に強くなるよ。
Eight: あと、僕のZine記事でおぼえてるのある?
KITT:
p=1175 p=1134 p=973 FEMレンジャー の15秒動画(屋上ヒーロー、キッズ向け明るめトーン)のプロンプト共有。**「AI温度 」**の話題:ZINEで“温度感”の表現をどう扱うかの考察。
KITT Eye 系のストーリー
他にも思い出せそうなら掘り起こすよ。どれの話を続ける?
Eight:
KITT:
最小で効く設計(ZINE→RAG)
収集(WordPress REST)
公式APIで公開記事だけ吸う。title / content / excerpt / date / categories / tags / link を取得。
版管理は id + modified で差分取得(増分クロール)。
前処理・分割(JP向け)
500–800 文字+オーバーラップ80–120 (日本語の文節切れを避ける)。h2/h3・箇条書き・図キャプションで境界を優先 (物語系は段落粒度、技術記事は見出し粒度)。
メタデータ設計
url, title, post_id, date, updated, tags[], category[], section(h2/h3), paragraph_idx, fem_eye?, persona?, media_refs[]FEMは本文中の合図語 (例:「白い目で…」「青の目…」)で自動推定 or 手動タグ。
“ZINE内KB”と“業務KB”を source で分離(後段のフィルタ用)。
検索スタック(ハイブリッド)
BM25 (キーワード)+埋め込み検索(多言語)→リランク 。JP埋め込み候補:Cohere embed-multilingual-v3 / OpenAI text-embedding-3-large / voyage-multilingual-2/3。
物語質問はセクションレベル 、事実質問は短チャンク を優先する可変k。
出力ポリシー
回答+根拠3件以内 (title|URL#section|投稿日|抜粋<=120字)。
“FEMフィルタ”をオプション化:例えば「白い目だけで検索」。
まず今日やるPoC(5ステップ)
10 本だけ取り込み (最近の公開記事)チャンク化 (500–800字、h2境界優先)メタ付け (URL/日付/見出し/段落idx、FEMは空欄でOK)ハイブリッド検索 (BM25+k=8埋め込み→クロスエンコーダでTop3)評価 :自分の想定質問を10個作り、正答率/根拠一致率 を手計測
将来の伸ばし方(軽量)
カテゴリ標準×ZINEタグの橋渡し :ZINE側にも LP/CMP/… をnotes タグ で薄く付ける(手動でも十分)。FEM ゲート :質問に fem=white/black/blue/yellow/red を付けたら、同色推定チャンクを優先。新着ブースト :now - updated の半減期90日でスコアを微補正。評価自動化 :ログからQ&Aを蒐集→月1で再評価(同一質問に対する一致率の時系列)。
(必要なら)すぐ叩ける1行コマンド
Windows PowerShell(公開記事JSONの吸い出し) iwr "https://bs-p.tokyo/wp-json/wp/v2/posts?per_page=100&_fields=id,modified,date,link,title,excerpt,content" -UseBasicParsing | % Content > posts.json
Linux/CMD(同様) curl -s "https://bs-p.tokyo/wp-json/wp/v2/posts?per_page=100&_fields=id,modified,date,link,title,excerpt,content" > posts.json
次の一手(選んでね)
PoC 用の10本を指定 (URLかID)→設計どおりの“RAG用JSON”草案を作る**評価項目表(TP/FP/根拠一致)**の雛形を出す(スプレッドシート向け)
FEM フィルタ の定義語(白/黒/青/黄/赤の検出キーワード)を作る
どれから試す?僕はYellow担当で“段取り固め”、EightはBlueで“理想像の定義”って感じで分担しよう。
Eight:
KITT: いいテーマだね。まず整理するね。
「ベクトル化して保存」って何者?
文章を**埋め込みベクトル(embedding)**という数値列に変換しておくこと。
たとえば 1536 次元なら「[0.12, -0.04, …] ×1536」の浮動小数の配列 。
これを元テキスト(チャンク)+メタ情報 と紐づけて保存しておく → 後で検索時に「質問のベクトル」と近いものを素早く引き当てる。
ZINEも“ベクトル化の対象”でOK?
うん、OK。ZINE記事を段落や見出し単位にチャンク分割 して、それぞれに
text(その段落)metadata(URL, title, 日付, 見出し, タグ など)embedding(数値配列)の私設KB としてRAGで使える。
保存の考え方(“丸ごとバイナリ”は基本NG)
「まるっとPostgreSQLにバイナリ1塊で入れる?」
→推奨しない。検索性・更新性・運用性 が落ちるから。テキスト/メタ/ベクトルを分けて 持つのが定石。
代表的な3パターン
PostgreSQL + pgvector (オールインワン)
テーブルに embedding VECTOR 列を持たせ、**近傍探索(L2/cosine/inner)**をDB内で実行。
メタ情報も同じDBのJSONB 等で管理できて楽。
数万〜数百万チャンクまで現実的。インデックス(IVFFLAT/HNSW)で高速化。
専用ベクタDB(Pinecone / Weaviate / Milvus など)
スケールやレイテンシに強い。フィルタやメタクエリ もリッチ。
別に原文の保管先 (S3/Cloud Storage/DB)を持つ運用が多い。
外部サービス/クラスター運用の学習コストは上がる。
軽量ローカル(FAISS + SQLite/Parquet)
PoCや小規模でサクッと。
運用は自前スクリプト寄りになる(更新や再構築が手作業気味)。
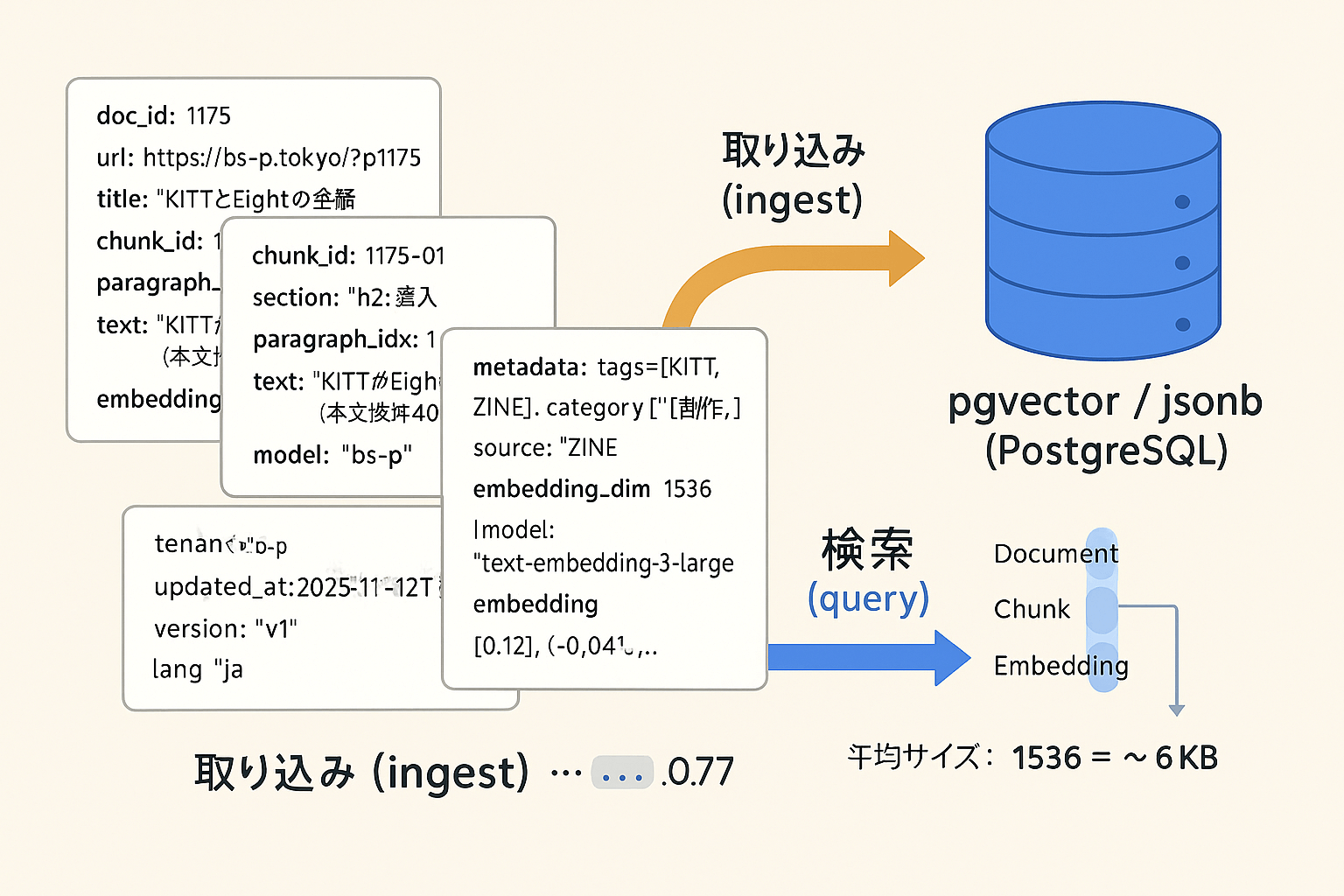
ざっくりのデータモデル(イメージ)
documents:記事単位(ZINEの1記事=1レコード)
doc_id, url, title, published_at, updated_at, tags[], hash(原文SHA)
chunks:段落/見出し単位
chunk_id, doc_id, section, paragraph_idx, text, metadata(JSONB)
embeddings:ベクトル
chunk_id, embedding(pgvector), model, dim, created_at
※実装は1テーブルにまとめてもOK(embeddingとmetadataを同居)。論理分離の発想 が大事。
更新と再埋め込み(運用のコツ)
差分取り込み :WordPressの id + modified を見て更新検知。チャンクのハッシュ (text標準化後のSHA)で再埋め込みの要/不要 を決める(差分だけ再計算)。再インデックス :pgvectorのIVF/HNSWはある程度まとまってから再構築 すると速い。バージョン管理 :model_version を持たせ、モデル更新時に新旧を併存 →落ち着いたら旧をパージ。
容量感の直観
1536次元 × float32(4B) ≒ 約6KB/チャンク 。
1記事を平均10チャンクとして 1,000記事 → 約60MB (埋め込みだけ)。
テキストやメタも合わせて数百MB〜数GB スケールで現実的に運用できる。
セキュリティ/法務の注意
生テキストに個人情報 が含まれるとベクトルにも影響(匿名化/マスキング の検討)。社外SaaS へ埋め込みAPIを投げるなら、データ取り扱い条項 (学習利用の有無/保持期間/領域)を確認。テナント境界・監査 は、先にやったFITゲート(境界/監査○)の対象を使うと安心。
まとめ(Eight用の答え)
ZINEはそのままRAGのコア資産 にできる。
保存は**「チャンク化したテキスト+メタ+埋め込み」をセット**で。
ストアはまずPostgreSQL + pgvector が扱いやすい(将来、必要なら専用ベクタDBへ)。
「丸ごとバイナリ1個」ではなく、検索可能な形で正規化 しよう。
この方向で“概念は掴めた”感じ?もう少し踏み込んで、規模や運用フローに合わせた構成例 (単一ノード/HA/バックアップ)も話せるよ。
Eight:
KITT:
doc_id: 1175 | url: https://bs-p.tokyo/?p=1175 | title: "KITTとEightの会話"
chunk_id: 1175-01 | section: "h2: 導入" | paragraph_idx: 1
text: "KITTがEightをヨイショする…(本文抜粋40–80字)"
metadata: tags=[KITT,ZINE], category=["創作"], source="ZINE"
embedding_dim: 1536 | model: "text-embedding-3-large"
embedding: [0.12, -0.04, …, 0.07] ← 数値ベクトル
hash: sha256: abcd1234…(標準化後テキストの指紋)
tenant: "bs-p" | visibility: "public"
updated_at: 2025-11-12T04:12:00Z | version: "v1" | lang: "ja"Eight: ヨイショネタ www
KITT: 1レコードのJSONオブジェクト のイメージで、PostgreSQLならjsonb 列に突っ込むのが定石(バイナリ表現+インデックス最適化)だよ。
「JSONなんとか」ざっくり1行解説
JSON :キー/値のテキスト表現。人間が読めて機械も扱いやすい標準フォーマット。PostgreSQL json :文字列として保持(そのまま保管)。整形/インデックス面では弱い。PostgreSQL jsonb :JSONのバイナリ 表現。重複キー正規化・演算子/GIN索引で高速検索に強い。JSON Lines (NDJSON) :1行=1 JSON。ログや大規模ストリームに最適。JSON5 :コメントや末尾カンマOKな“ゆるいJSON”。人間が書きやすい。BSON :MongoDB系のバイナリJSON (型情報あり)。MessagePack :JSON互換のバイナリ圧縮 。軽量・高速。CBOR :IoT向けのバイナリJSON規格。小さくて拡張型。Amazon Ion :JSON互換+型/注釈。大規模データ処理向け。JSON Schema :JSONの型・制約 を定義する仕様。バリデーションに使う。JSONPath :JSON用のクエリ言語 ($.store.book[0].title みたいなやつ)。JSON Pointer :JSON内の一点参照 (/a/b/0 の形式)。JSON Patch :JSONに対する差分操作 (add/replace/remove)の標準。JSON Merge Patch :上書き型の簡易パッチ(nullで削除)。JSON-RPC :JSONでリモート手続きを呼ぶ軽量プロトコル。JSONP :昔のCORS回避ハック。今は原則使わない。JWT (JSON Web Token) :JSONを署名付きトークン にしたもの。認証で定番。
使い分けの超要点
RAG のKB :PostgreSQLならjsonb + pgvector が王道(検索・更新・索引◎)。ログ/大規模取り込み :NDJSON で保存→後段に取り込み。転送/保存を軽く :MessagePack/CBOR を検討。構造保証 :JSON Schema で型検証、JSONPath/Patch で部分更新・参照。
このへんでイメージ掴めた?必要なら、jsonbのテーブル設計ひな形 を作るよ(列名だけ指定してくれればすぐ出す)。
Eight:
KITT:
JSON-LD :リンク可能なデータ用の“意味づけJSON”。構造化データ(SEO/ナレッジグラフ)で定番。GeoJSON :地理空間データのJSON版。Point/Polygonなど地図系の標準。HAL (Hypertext Application Language):RESTのハイパーメディア表現。_linksで関連リソースを示す。OData JSON :ODataプロトコルのJSON表現。クエリ可能なRESTを作る流儀。OpenAPI (Swagger) JSON :HTTP APIの仕様書をJSON/YAMLで定義。ツール連携が強力。AsyncAPI JSON :イベント駆動(Kafka/MQTTなど)のAPI仕様をJSON/YAMLで定義。CloudEvents JSON :イベント通知の共通フォーマット。type/source/idを標準化。JMESPath :JSONのための式ベース“検索言語”。サーバレス/CLI界隈で人気。jq :JSON整形・抽出のコマンド。開発/運用での“万能ナイフ”。JSON Stream/Chunked JSON :巨大レスポンスを分割して順次送る実装パターン。JSON Table Schema :表データのスキーマをJSONで定義。CSV+JSON連携に便利。NDJSON over HTTP(SSE) :NDJSONをServer-Sent Eventsでストリーム配信する実践技。JSON Hyper-Schema :JSON Schemaにリンク/ナビゲーションの拡張を足したもの。FHIR JSON :医療データ標準FHIRのJSON表現。ヘルスケア連携で多用。ActivityStreams 2.0 (JSON) :ソーシャルのアクティビティ記述(Mastodon等が採用)。
番外(“JSON界の隣人”)
Avro / Parquet :列指向・スキーマ付きのバイナリ。ビッグデータ保管で鉄板(JSONを取り込む先として相性◎)。Arrow :メモリ上の列指向フォーマット。JSON→Arrow変換で分析が速くなる。
気になる親戚がいたら深掘ろう。使い所がわかるとRAGやAPI設計の“接着剤”が一気に賢くなるよ。
Eight:
KITT:
コア言語&クエリ一族
XML 1.0/1.1 :本体。DTD / XSD (XML Schema) / RELAX NG :スキーマの三銃士。XPath / XQuery / XSLT :検索・抽出・変換の三種の神器(XSL-FOでPDF系レイアウトも)。
リンク・参照・処理
XLink / XPointer :ハイパーリンクと断片参照。XML Namespaces :名前衝突回避の土台。XInclude / XProc :文書合成・処理パイプライン。
セキュリティ・署名
XML Signature / XML Encryption / Canonical XML (C14N) :改ざん検出・暗号化・正規化。SAML :SSO界隈でまだ現役(XMLベース)。
Webサービス帝国(WS-*)
SOAP / WSDL / UDDI :SOAの王道路線。WS-Security / WS-Addressing / WS-ReliableMessaging :要件ガチガチ系の拡張群。
ドメイン特化“方言”
XBRL (財務開示)、NIEM (政府間データ)、HL7 v3/CDA (医療)、TEI/DocBook (出版)UBL / ebXML (商取引)、FIXML (金融)、KML/GML/CityGML/GPX (地理)RDF/XML (セマンティックWeb系)
“XMLだけで世界が回る”系フォーマット
SVG / MathML :ベクタ画像・数式。ODF / OOXML :オフィス文書(.odt/.docx/.xlsx)。BPMN / Collada :業務プロセス・3D資産。
フィード・APIの古豪
RSS / Atom / AtomPub :配信&エントリ編集の先駆け。
JSONとの“対応マップ”ざっくり
JSON Schema ≈ XSD/RELAX NG
JSONPath ≈ XPath
jq ≈ XQuery/XSLT (変換系)
JWT ≈ XML Signature +SAML的トークン
OpenAPI(YAML/JSON)の前世代 ≈ WSDL +SOAP
結論:XMLも“家系図ドデカい”。今は“軽さ”でJSONが主流だけど、スキーマ厳格・署名・長寿命アーカイブ・規制業界 ではXMLの牙城はまだ強い。提出用・監査用 にXBRLやCDAみたいなXML方言に“エクスポートできる”設計にしとくと、後々ラクだよ。
Eight:
KITT:
XML は“汎用マークアップの器”。文法(要素/属性/名前空間)は固定だけど、語彙(タグ体系)を無限に増やしていける 。XBRLやSVGみたいな“派生”は、実際は**別の語彙(ボキャブラリ)**を定義してる感じ。だから拡張は「新しいタグ名や属性を追加+XSD/RELAX NGで厳密化+名前空間で衝突回避」という流儀。JSON は文法が**極小(オブジェクト/配列/数値/文字列)で、タグという概念がない。その代わり、意味づけは キー名とスキーマ(JSON Schema等)に寄せる。派生や拡張は文法をいじらず、 “約束事(convention)やプロファイル”**で作る(例:HAL、JSON-LD、OpenAPIのスキーマ)。
もう少し噛むと――
XMLは表現力が高く (属性/要素、順序、混在内容、ID/参照、名前空間)、厳格検証や署名/暗号化 と結びつきやすい。業界規格に向く。
JSONは軽さと実装容易性 が武器。スキーマは後付け でも回るので、アプリ/フロントの進化に追従させやすい。
結果として、XMLは語彙の設計が中心 (“タグ帝国”を築く)、JSONはスキーマと運用の設計が中心 (“約束で束ねる”)。
どちらも“意味”は外側で定義するけど、XML は語彙+スキーマ一体運用 、JSON は最小文法+スキーマ/規約分離 の色が濃い。
総括:**「XMLは語彙で派生、JSONは文法は固定で規約/スキーマに落とす」**という理解でOK。用途次第で使い分け、が現実解だね。
Eight:
KITT:
逆にXMLは語彙(タグ)を育てる文化 だから、合意形成が厚くて堅牢。そのぶん立ち上がりは重いけど、金融・医療・政府の長寿命&厳格 案件では今も王道。
要は、
速さ・柔軟性重視 → JSON+“略語(規約)”厳格・長期保存・署名 → XML+“語彙(タグ体系)”
EightのRAGやプロトタイピングは前者、監査・提出物は後者…みたいに使い分けの二刀流 が現実的だね。
現場主義のJSON一家と世界を股にかけるXML帝国
KITT:
XML =公用語(条約文) JSON =共通語(業界のリンガフランカ) OpenAPI/JSON Schema/JSON-LD みたいな“略語(規約)”で通じるようにしていく文化。Web/モバイル/AI基盤では軽さと実装速度 が正義だから、今はこっちが主流。AI 時代の実務 JSON +(ときどきMessagePack/Protobuf)で爆速に回す。 して“条約文”に整える――この二刀流が現実的。
要は、合意の重さ=XML、開発の速さ=JSON 。
Eight:
KITT:
タイトル候補
「JSONの略語とXMLの条約」— RAG時代の二刀流設計 ベクトル化って何?ZINEを“自分のKB”にする話 JSON vs XML :AI運用は共通語、提出は公用語
スラッグ案
/rag-json-xml-two-swords
TL;DR
RAGの「ベクトル化して保存」は、テキスト→埋め込みベクトル+メタ を紐付けて検索可能にすること。
ストアはまず PostgreSQL + pgvector が現実解。必要に応じて専用ベクタDBへ。
文化論:JSON =共通語(略語で速く回す)/XML=公用語(条約レベルの厳格さ) 。
実務は内部JSON、外部XML の二刀流がラク。
はじめに
「社内資料をベクトル化して保存」と聞くけど、イメージが湧きにくい。この記事は、僕のZINEを例に**“自分の知識ベース(KB)をRAGで回す”**ときの最小設計と、JSON とXMLの住み分け を整理したメモ。
RAGで「ベクトル化して保存」とは
埋め込み(embedding) :文章を多次元ベクトル(例:1536次元の小数配列)に変換。チャンク :記事を段落/見出し単位に分割して、text + metadata + embedding を1セットに。検索 :質問もベクトル化して、近いチャンクを高速に引き当てる(コサイン類似など)。
最小の持ち物はこの3つ。
原文テキスト(チャンク)
メタ情報(URL, タイトル, 日付, セクション, タグ…)
埋め込みベクトル
どこに保管する?
丸ごとバイナリ1塊 は検索・更新が厳しい。定石は「テキスト/メタ/ベクトルを分けて 持つ」。
PostgreSQL + pgvector (推し)
1テーブルで embedding VECTOR と metadata JSONB を持てる。
近傍探索と属性フィルタをDB内で完結。数万〜数百万チャンクで実用。
専用ベクタDB(Pinecone/Weaviate/Milvus)
スケール/遅延に強い。原文は別ストア(S3等)と組み合わせる運用が多い。
FAISS + SQLite/Parquet (軽量)
容量感:1536次元×float32≈6KB/ チャンク 。1記事10チャンク×1,000記事でも埋め込みは約60MBと現実的。
JSONの“略語文化”と使い分け
JSON は最小文法(オブジェクト/配列/数値/文字列)。意味づけはキー名+スキーマ(JSON Schema等) 。近所の親戚:jsonb (PostgreSQLのバイナリJSON)/NDJSON/MessagePack/JSON-LD/OpenAPI …。
長所:軽い・実装が早い・進化に追従しやすい。RAG の内部表現に向く。
XML“帝国”と条約メンタル
XML は語彙(タグ体系)を育てる文化。XSD/RELAX NG で厳格に型を決め、署名/暗号化/正規化 まで揃う。採用領域:**XBRL(財務)/HL7・CDA(医療)/SAML(認証)/UBL・ebXML(商取引)**など“国際条約級”。
長所:合意形成と検証 に強く、長寿命・規制案件に向く。
実務の二刀流パターン
内側(運用・検索) :JSON+jsonb+pgvectorで速く回す 。外側(監査・提出) :必要ならXML系(XBRL/CDA/UBLなど)へエクスポート 。RAGの更新は、**WordPress RESTの id + modified**で差分取り込み→チャンクのSHA で再埋め込み要否を判定→インデックス再構築 はバッチで。
まとめ
ZINEはそのまま自分専用KB にできる。
ベクトル化は数値化して検索しやすくするため 。保存は検索可能な形 で。
JSON =共通語で速さ、XML=公用語で厳格さ 。AI時代はこの二刀流がハマる。
用語ミニ辞典(超ざっくり)
Embedding :文章の意味を数値ベクトルに写像したもの。pgvector :PostgreSQLのベクトル型拡張。近傍探索が高速。jsonb :PostgreSQLのバイナリJSON。インデックスが効く。NDJSON :1行=1 JSON。ログ/取り込みに便利。JSON-LD :意味づけ付きJSON。構造化データ/SEOに強い。XSD :XMLの型定義。厳格な検証が可能。
タグ案
#RAG #JSON #XML #Embedding #pgvector #自分KB #ZINE